The inherent structure observed in natural data implies that the data admits a sparse representation in an appropriate coordinate system. In other words, if natural data is expressed in a well-chosen basis, only a few parameters are required to characterize the modes that are active, and in what proportion. All of data compression relies on sparsity, whereby a signal is represented more efficiently in terms of the sparse vector of coefficients in a generic transform basis, such as Fourier or wavelet bases. Recent fundamental advances in mathematics have turned this paradigm upside down. Instead of collecting a high-dimensional measurement and then compressing, it is now possible to acquire compressed measurements and solve for the sparsest high-dimensional signal that is consistent with the measurements. This so-called compressed sensing is a valuable new perspective that is also relevant for complex systems in engineering, with potential to revolutionize data acquisition and processing. In this chapter, we discuss the fundamental principles of sparsity and compression as well as the mathematical theory that enables compressed sensing, all worked out on motivating examples.
Our discussion on sparsity and compressed sensing will necessarily involve the critically important fields of optimization and statistics. Sparsity is a useful perspective to promote parsimonious models that avoid overfitting and remain interpretable because they have the minimal number of terms required to explain the data. This is related to Occam's razor, which states that the simplest explanation is generally the correct one. Sparse optimization is also useful for adding robustness with respect to outliers and missing data, which generally skew the results of least-squares regression, such as the SVD.
Youtube playlist: Sparsity and Compressed Sensing
Our discussion on sparsity and compressed sensing will necessarily involve the critically important fields of optimization and statistics. Sparsity is a useful perspective to promote parsimonious models that avoid overfitting and remain interpretable because they have the minimal number of terms required to explain the data. This is related to Occam's razor, which states that the simplest explanation is generally the correct one. Sparse optimization is also useful for adding robustness with respect to outliers and missing data, which generally skew the results of least-squares regression, such as the SVD.
Youtube playlist: Sparsity and Compressed Sensing
Section 3.1: Sparsity and Compression

[ Overview ] [ Vastness of Image Space ] [ What is Sparsity? ]

Section 3.3: Compressed Sensing Examples
Underdetermined systems and CS [ Matlab ] [ Python ] [ Nyquist Theorem ] [ Beating Nyquist w CS ] [ Matlab ] [ Python ]
Section 3.4: The Geometry of Compression

Section 3.5: Sparse Regression

[ Sparse Regression with LASSO ] [ Robust Regression with L1 ] [ Matlab ] [ Python ]


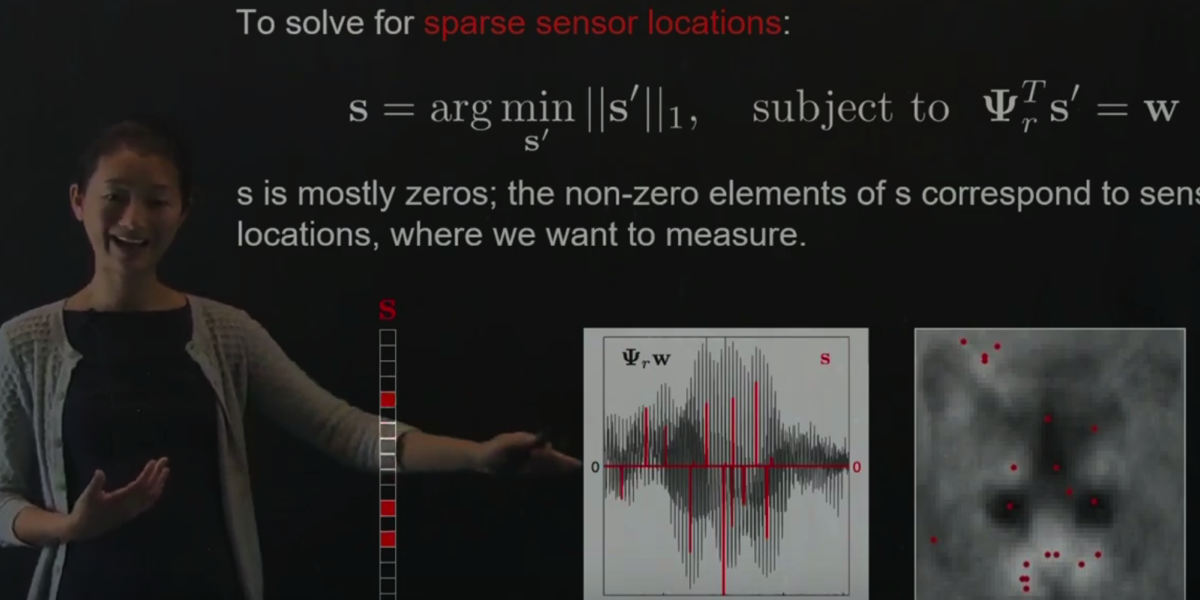
Section 3.8: Sparse Sensor Placement Optimization